
Have you ever broken a system? Introduced an error in configuration? Or simply didn’t test all use cases on your laptop? How do we prevent misconfiguration when working in large teams? Code reviews, configuration management, and manual testing are not enough, especially when you roll your changes to production.
The truth is, configuration files are fragile.
Changing configuration naturally comes with a risk of introducing failed deployments. Whether it’s a typo or a bug you introduce, it’s still hard to iterate quickly on configuration changes. This is especially important when working with multiple teams introducing frequent configuration changes. Additionally, it can also get really frustrating when a change in configuration breaks logging in your production environment.
At Agolo, we use Logstash as part of our logging stack. We use the popular Elastic stack including Filebeat, Logstash, ElasticSearch, and Kibana
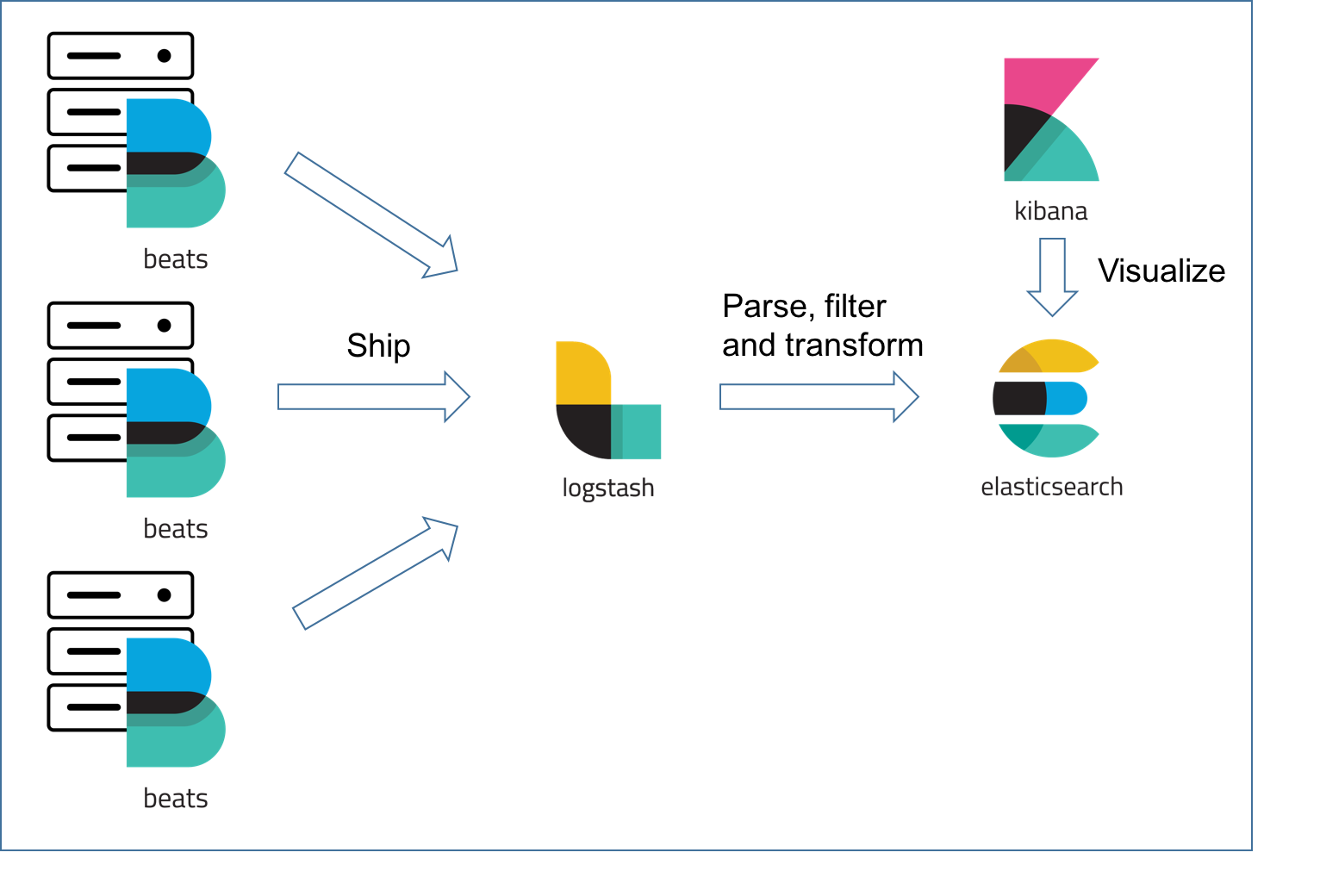
In this post, I’ll focus on how we managed to safely iterate over Logstash configurations while respecting Agile principles of fast iteration and small feedback loops. For those who don’t know, Logstash is a log ingestion service that takes care of parsing, mutating, and cleaning up logs in a structured JSON format before getting them stored in a database — ElasticSearch.
Configuration Nightmare
When dealing with many different service log formats, it can be challenging to test Logstash config files. It’s even more daunting when the same service outputs logs in a plurality of formats. Long-term, it’s best to assign service owners tickets to refactor their logs. Ideally, all your logs are in a structured format such as JSON. Unfortunately, that’s not true for all services in the real world. But sometimes you don’t have the luxury to reformat logs. It can be quite an effort to refactor hundreds or thousands of lines of code, especially when logs are not in a structured format. You almost have to handle log by log and make a logical decision on what gets parsed and what doesn’t. You might even be dealing with critical issues on legacy or closed systems that you inherited and don’t have the internal knowledge of the service to refactor its logs. This is where automated testing can help. That’s right… tests for your configuration files! I found myself dealing with multiple log sources with a variety of complex log formats.
Performing diff algorithms in my head got tiring every time I made a change to my grok patterns.
At Agolo, we deal with a lot of data traffic. And with that comes a lot of logging from each microservice. We log more than 100 million+ logs per day (~1200 logs/second). Hence, mistakes in configuration files are too costly. Making typos or mismatches in grok patterns is common and a necessary part of iterating over configuration changes. I found myself breaking Logstash quite often because of edge cases I didn’t think about.
How do we apply DevOps principles to solve this problem? What if we could run unit or integration tests against Logstash configurations? I asked myself these questions and started searching around for existing solutions or tools, but none of them met the requirements I had:
- Testing framework
- Easy to write tests
- No Domain-Specific-Language (DSL)
- Fast feedback loop
Dealing with Tight-Coupling
So I wrote Logstash Test Runner: An opinionated testing framework to help with testing Logstash configurations. It’s open-sourced under the MIT license. Try it and start contributing!
Logstash Test Runner makes it easy to write tests because all you need to provide are familiar to you — a log file, a Logstash config file, and your expected output. You don’t need to know Ruby or any other DSLs. The only dependency is Logstash itself running inside Docker. If you know how to write Logstash configurations, it’s immediately familiar. The workflow is simple and you get test results pretty quickly; tightening the feedback loop. Plus, you save a lot of time — *cough* downtime *cough* — by being able to test production logs locally.
Here’s what the workflow looks like…

The way it works is, you create three files
- input log file: a set of known logs from your microservice
- logstash config file: configuration you want to ship to production
- expected output log file: expected output from Logstash
Tests are stored in a structured directory
test.sh
__tests__
service1
input.log
logstash.conf
output.log
service2
input.log
logstash.conf
output.log
...
You can then run your tests with
./test.sh __tests__
With an opinionated testing file structure, you can split tests per configuration file. The structure above is not enforced but more like a convention. Each test is run in a Docker container using the Logstash base image. The input file is piped via stdin and its output is compared to the expected output file. If they match, the test passes. Otherwise, a colored JSON diff is displayed with the differences between the outputs.

But how do we deal with changing values, like timestamps?
By default, ‘@timestamp’ column is ignored. You can also pass custom columns you would like to ignore as part of the diffing stage.
Conclusion
What’s great about this approach is that it can be automated and added as part of your CI/CD pipeline such that every configuration change goes through integration testing. You can then be sure that your logs are still parsed correctly despite your configuration changes.
A lot concepts from traditional software engineering can be learned from in Ops teams. Running tests for infrastructure tools like Logstash fits within the practices of DevOps (Build → Test → Ship → Run). I think the idea of testing infrastructure configurations should become more commonly practiced and can have tremendous value in increasing infrastructure reliability and delivery.
